
Using support vector classification for SAR of fentanyl derivatives1
Introduction
Fentanyl, a synthetic opioid commonly used during anesthesia, is also used to relieve pain in terminally ill patients[1]. Fentanyl is lipophilic and has high potency as an analgesic or anesthetic, which can rapidly penetrate the central nervous system once taken by patients[2].
Support vector classification (SVC) is a machine learning method based on the support vector machine (SVM) proposed by Vladimir N Vapnik[3]. It has been recently proposed as a very effective method for pattern recognition. It has also been successfully used in such research fields as vowel recognition[4], drug design[5], combinatorial chemistry[6], prediction of beta-turn and alpha-turn types of proteins etc[7,8]. In the present work, the qualitative model was built based on SVC, with structural descriptors calculated by using the software Hyperchem, to explore the structure-activity relationship of fentanyl derivatives. The outstanding performance of the SVC model proved the significance of this method.
Methodology
Computational theory The SVC method was used in this work. The geometrical interpretation of SVC is that it chooses the optimal separating surface, ie the hyperplane equidistant from two classes. This optimal separating hyperplane has many nice statistical properties, which are detailed by Vapnik[3,9].
Consider the problem of separating the set of training vectors belonging to two separate classes, (y1, x1), .., (yn, xn), x∈Rm, y∈-1, +1, with a hyperplane
If the training data are linearly separable, then there exists a pair (w, b) such that:
The decision rule is:
where w is termed the weight vector and b the bias. Without loss of generality the pair (w, b) can be rescaled such that:
The learning problem is hence reformulated as: minimize ||w||2 subject to the constraints of linear separability. This is equivalent to maximizing the distance, normal to the hyperplane, between the convex hulls of two classes. The optimization is now a quadratic programming (QP) problem:subject to yi(wTxi+b)≥1, i=1, 2, .., l.
This problem has a global optimum. The Lagrangian for this problem is:
Hence we can write:
In the case where a linear boundary is inappropriate the SVC can map the input vector, x, into a high dimensional feature space, F. By choosing a non-linear mapping Φ, the SVC constructs an optimal separating hyperplane in this higher dimensional space. Among the acceptable mappings are polynomials, radial basis functions and certain sigmoid functions. Then the optimization problem becomes,
Implementation of SVC The SVM software package including SVC was programmed according to the literature[3]. The software was tested in some applications in chemistry and chemical engineering[9,10]. All computations were carried out on a Pentium IV computer with a 1.3G Hz processor.
Results
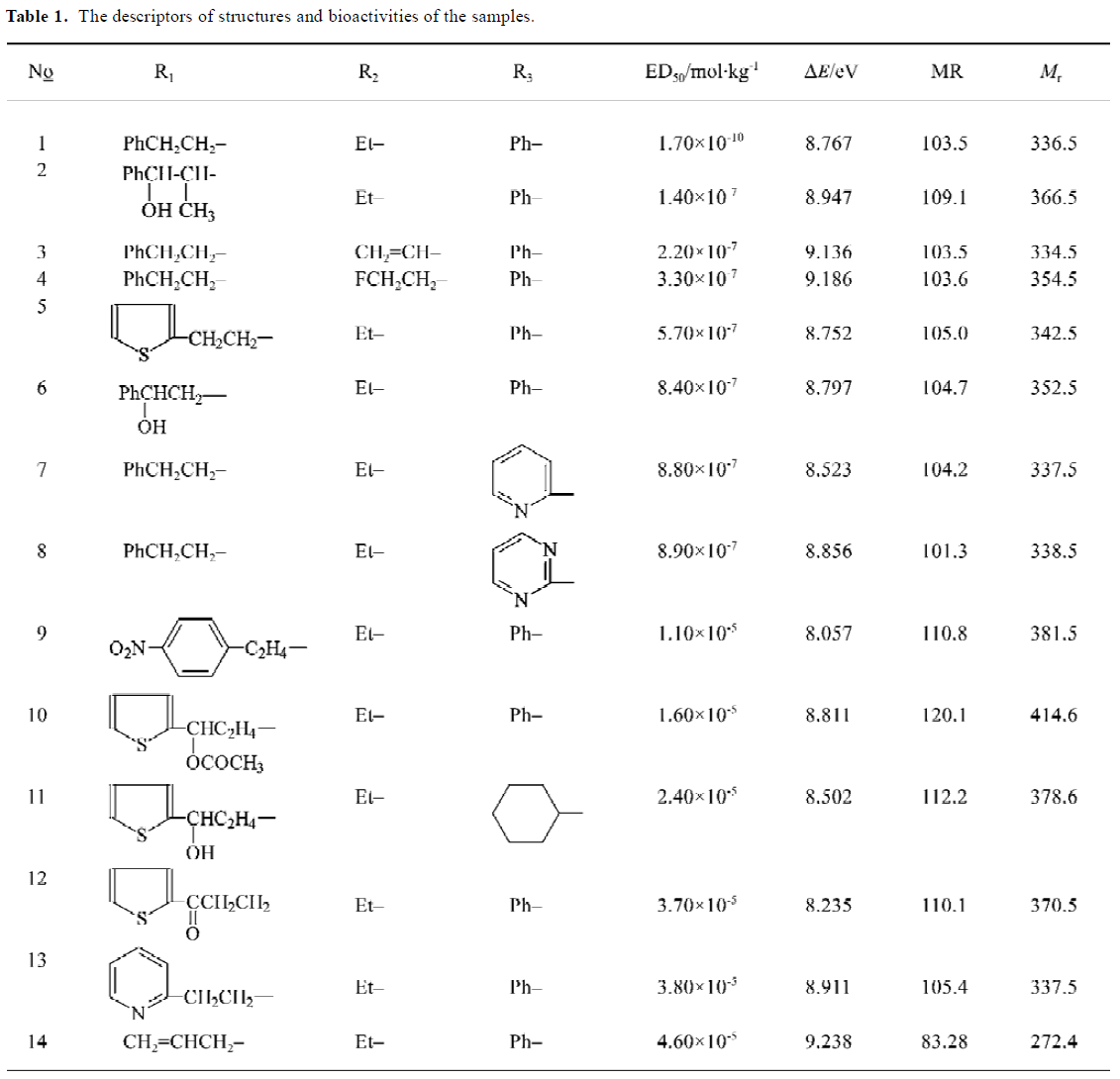
Data set The data set consists of 14 fentanyl derivatives available[11]. The molecular formula investigated in this work is shown in Figure 1. The substituents of the compounds include R1, R2, and R3. The data set can be divided into two classes according to the analgesic bioactivities ED50 (hot plate method in mice)[11] of samples. Here Class 1 contains the compounds with high activities, ie the molecules with ED50<1.0×10-6 (mol/kg). Class 2 contains the compounds with low activities, ie the molecules with ED50>1.0×10-6 (mol/kg).
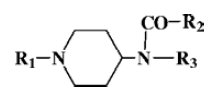
Computation of descriptors The three-dimensional structures of the molecules were drawn, and optimized with the software Hyperchem3 (Release 7.0 for Windows Molecular Modeling System, Hypercube Inc. 2002), which was utilized for the computation of MM+ and PM3 later. Prior to the semi-empirical computation of quantum chemistry, all structures of the compounds were submitted to MM+ computation of molecular mechanics for energy optimization. The computations were carried out at a restricted Hartree-Fock level with no configuration interaction. The molecular structures were optimized using the Polak-Ribiere algorithm until the root-mean-square gradient was 0.001. Only the most stable conformation of molecule has been used to obtain the structural descriptors via the computational results of semi-empirical method PM3. Using the software Hyperchem3, the descriptors obtained were as follows: HOMO (highest occupied molecular orbital energy), LUMO (lowest empty molecular orbital energy), ΔE (energy difference between HOMO and LUMO), TE (total energy), HF (heat of formation), EE (electronic energy), SA (surface area), MV (molecular volume), lgP (partition coefficient), MR (molecular refractivity), MP (molecular polarizability), Mr (molecular weight), N1 (charge density of the atom N connecting with R1), C2 (charge density of the atom C connecting with R2), N3 (charge density of the atom N connecting with R3).
Selection of descriptors The selection of descriptors is a relatively tough job due to the redundancy of some parameters. The result used to depend on the experience of the researcher. Recently, some of promising results have been reported on the problem of feature selection[12,13]. In this work, the entropy method was applied to the selection of descriptors[14]. Through the computation of entropy for the data set available, the three descriptors (ΔE, MR, Mr) are determined to be more important than the others. Table 1 lists the samples with bioactivity ED50 and selected descriptors, including ΔE, MR, and Mr. It should be mentioned that there possibly exist other combinations of descriptors useful for the classification of data set used here, but the three descriptors above are enough to be used as the determining factors for the prediction of activities of the compounds (refer to the good results described in the following sections).
Full table
Selection of the kernel function and the capacity of parameter C used in the SVC model Similar to other multivariate statistical models, the performance of SVC is related to dependent and independent variables as well as the combination of parameters used in a model. In the computation of SVC, we have to deal with the capacity parameter C (also called the regularization parameter) and the kernel type used in modeling.
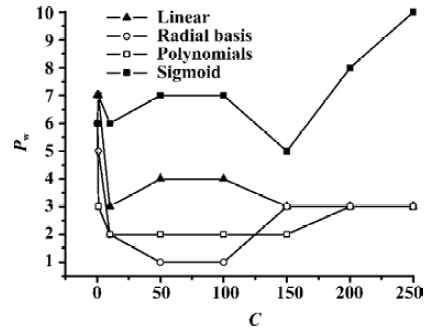
In this work, the cross validation test, using the leaving-one-out (LOO) method was undertaken to find a suitable capacity parameter C and the appropriate kernel function for the SVC model. Suppose that Pw is the number of samples misclassified using the LOO method; it can then be employed as a criterion to obtain the appropriate kernel function and the optimal capacity parameter C. Figure 2 illustrated Pw (concerned with different kernel functions including linear, radial, polynomial and sigmoid functions) versus the capacity parameter C from 0.1 to 250. It was found that the SVC model with the best performance could be ascertained by using the radial kernel function with capacity parameter C from 50 to 100.
Modeling of SVC According to the results we abtained, the optimal model of SVC for discriminating between high and low activities of compounds could be built as follows, using the radial kernel function with capacity parameter C=100:
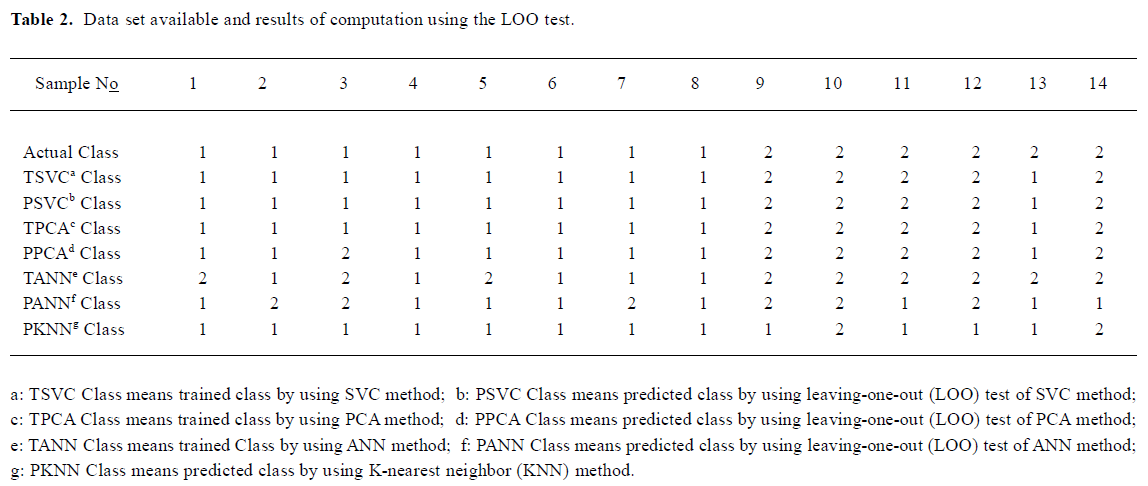
where σ=1, b=0.68, αi=36.1 (i=2), 21.8 (i=3), 55.1 (i=5), 19.3 (i=7), 0 (i=10), 30.5 (i=11), 100 (i=13), 1.84 (i=14),correspond to the Lagrange multipliers of support vectors, while all the others. αi=0. yi=1 for the samples of class 1; yi=-1 for the samples of class 2. xi is a vector (pattern of sample) with unknown activity to be discriminated, xi is one of the support vectors. Based on this SVC model, the samples were discriminated as those of high bioactivities (ED50<1.0×10-6 mol/kg), if g(x)≥0. Using SVC model for the classification of activities of fentanyl derivatives, the accuracy of classification was 93% by using radial basis kernel functions with the capacity parameter C=100. Table 2 lists the trained results from SVC model obtained above. Figure 3 illustrated the effect of classification with trained SVC model. It was found that only one sample (compound N
Full table
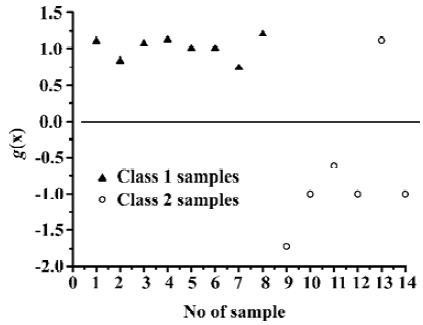
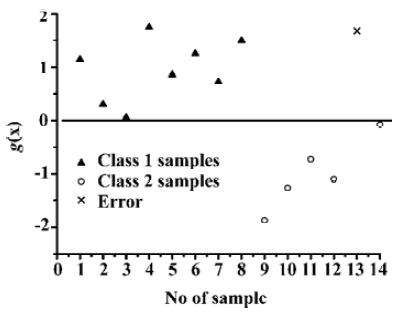
Results of cross validation tests Figure 4 illustrated the effect of the cross validation test using LOO method of SVC. It is obvious that the quality of prediction results (Figure 4) is as good as that of trained results (Figure 3), also with only one sample (compound N
For comparisons with other data mining methods, three commonly used chemometric methods including principal component analysis (PCA), K-nearest neighbor (KNN) and artificial neural network (ANN) were utilized to investigate SAR of fentanyl derivatives, with special consideration of their predictive ability (generalization ability) from cross validation tests using LOO method.
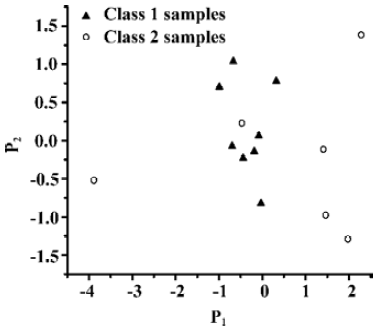
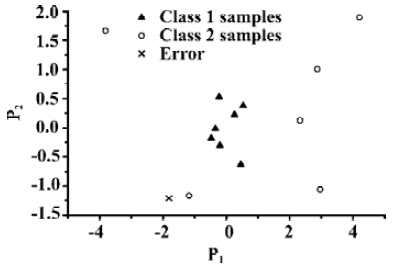
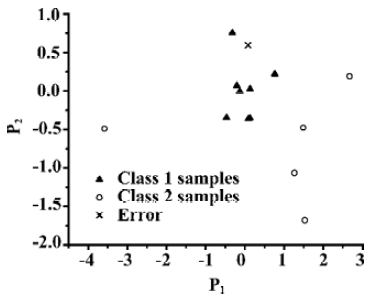
Figure 5 illustrated the trained results of classification for the same data set using PCA method. It could be seen from Figure 5 that the quality of classification results was as good as thoses from the SVC model, with only one sample misclassified. However, there were two samples predicted wrong from the results of cross validation test using LOO method of PCA. Figure 6 and Figure 7 illustrated the locations of samples marked N
KNN method, as a helpful pattern recognition tool, was utilized to discriminate between high and low activities of compounds for the same data set, with the accuracy of prediction being 71% (K=5). Obviously, the predictive ability of KNN model was poor compared to that of SVC model in this situation.
So far as BP ANN model is concerned, ANN with three layers was used to build the relationship between the features and activities of compounds. The number of hidden nodes was three; the transformation function used was Sigmoid; the number of training steps was 250 000. Table 2 lists both trained results and predicted results using LOO method, based on the ANN model built. It was found from Table 2 that the trained results of classification were not as good as the predicted ones. There were only three (N
Discussion
The SVC has been introduced as a robust and highly accurate intelligent classification technique, likely to be a useful chemometrics tool. On a simple but real chemometric problem the predictive ability of SVC for the data set available here outperforms that of PCA, KNN and ANN methods, which are the most frequently used chemometric techniques. The SVC exhibits better overall performance because it embodies the structural risk minimization principle. It has an advantage over the other techniques because it converges to the global optimum, and not to a local optimum that depends on the initialization and parameters affecting the rate of convergence. It can be concluded that (1) the selected descriptors can account for the features of the fentanyl derivatives; (2) the SVC is a very promising tool for the approximation of qualitative classification and (3) the SVC is especially suitable for finding the regularities of the small data set, ie, data set with fewer samples, giving modeling results with good generalization ability.
Training and optimization using SVC are easier and faster compared with other machine learning techniques, because there are fewer free parameters and only support vectors (only a fraction of all data) are used in the generalization process. The results show that the SVC is a good approach for predicting the classes of fentanyl derivatives. At the same time, the models proposed could identify and provide some insight into what features are related to the classification of these compounds and afford some instruction for further recognizing new fentanyl derivatives. It should be noted that no single method or paradigm is uniformly superior, although the preliminary evidence presented in this work suggests that the SVC is a data-mining tool with great potential in chemometric application.
Footnote
Project supported by the National Natural Science Foundation of China (N
References
- Maddocks I. Subcutaneous administration of fluid and drugs in palliative care. Aust J Hosp Pharm 1992;22:181-4.
- Gerak LR, Moerschbaecher JM, Bagley JR, Brockunier LL, France CP. Effects of a novel fentanyl derivative on drug discrimination and learning in rhesus monkeys. Pharmacol Biochem Behav 1999;64:367-71.
- Vapnik VN. Statistical learning theory. New York: John Wiley and Sons; USA; 1998.
- Wan V, Campbell WM. Support vector machines for speaker verification and identification. Neural networks for signal processing X, Proceedings of the 2000 IEEE Signal Processing Workshop. IEEE 2000; 2: 775–84.
- Burbidge R, Trotter M, Buxton B, Holden S. Drug design by machine learning support vector machines for pharmaceutical data analysis. Comput Chem 2001;26:5-14.
- Trotter M, Buxton B, Holden S. Support vector machines in combinatorial chemistry. Meas Control 2001;34:235-9.
- Cai YD, Liu XJ, Li YX, Xu XB, Chou KC. Prediction of beta-turns with learning machines. Peptides 2003;24:665-9.
- Cai YD, Feng KY, Li YX, Chou KC. Support vector machine for predicting alpha-turn types. Peptides 2003;24:629-30.
- Lu WC, Chen NY, Ye CZ, Li GZ. Introduction to the algorithm of support vector machine and the software ChemSVM. Comput Appl Chem 2002;19:697-702.
- Chen NY, Lu WC. Support vector machine applied to chemistry and chemical technology. Comput Appl Chem 2002;19:673-6.
- Zhu YC, Fang SN, Ge BL, Li QZ, Dai QY, Huang ZM, et al. Studies on potent analgesics 2. Synthesis and analgesic activity of the derivatives. Acta Pharm Sin 1981;16:97-104. [in Chinese].
- Li GZ, Wang ZX, Yang J, Yao LX, Chen NY. A SVM-based feature selection method and its applications. Comput Appl Chem 2002;19:703-5.
- Dash M, Liu H. Feature selection for classification. Intell Data Anal 1997;1:131-56.
- Chen NY, Qin P, Chen RL, Lu WC. Pattern recognition applied to chemistry and chemistral industry. Beijing: Science Press; 2000.